Archival Storage
What is CAC Archival Storage?
- CAC Archival Storage provides low-cost, high-performance option for storing research data.
- CAC Archival Storage has a direct 100 Gbps connection to Internet2.
- CAC Archival Storage is not mountable by running jobs, instead the user must transfer their data from the CAC Archival Storage to an accessible server using Globus.
- Data in CAC Archival Storage is intended to be an additional copy of user data; CAC Archival Storage is not backed up or snapshotted.
- All CAC resources are suitable for unregulated, non-confidential data (reference for details).
- Globus users have easy access to add, delete, and share their data using any Globus endpoints.
- Some of the Globus endpoints available include:
- CAC user home directories (cac#home)
- TACC sites - search for collections by name:
- TACC Frontera
- TACC Stampede3
- TACC Ranch (tape archival)
- Most NSF ACCESS sites can also be found by name.
First Step - Enable (or create) CAC project for Archival Storage and add users where appropriate
- To use the CAC Archival Storage service, you must be a user of a CAC project where Archival Storage is enabled.
- The project PI can add users and verify that Archival Storage is enabled at the CAC portal. See portal documentation for details.
- Don't have a CAC project? How to Start a Project.
Second Step - Log into Globus
CAC Archival Storage is accessible only through Globus. Log into Globus using these login instructions.
When logging into Globus,
- Cornell users should select Cornell University under Use your existing organizational login, or
- Weill Cornell Medicine users should select Weill Cornell Medical College,
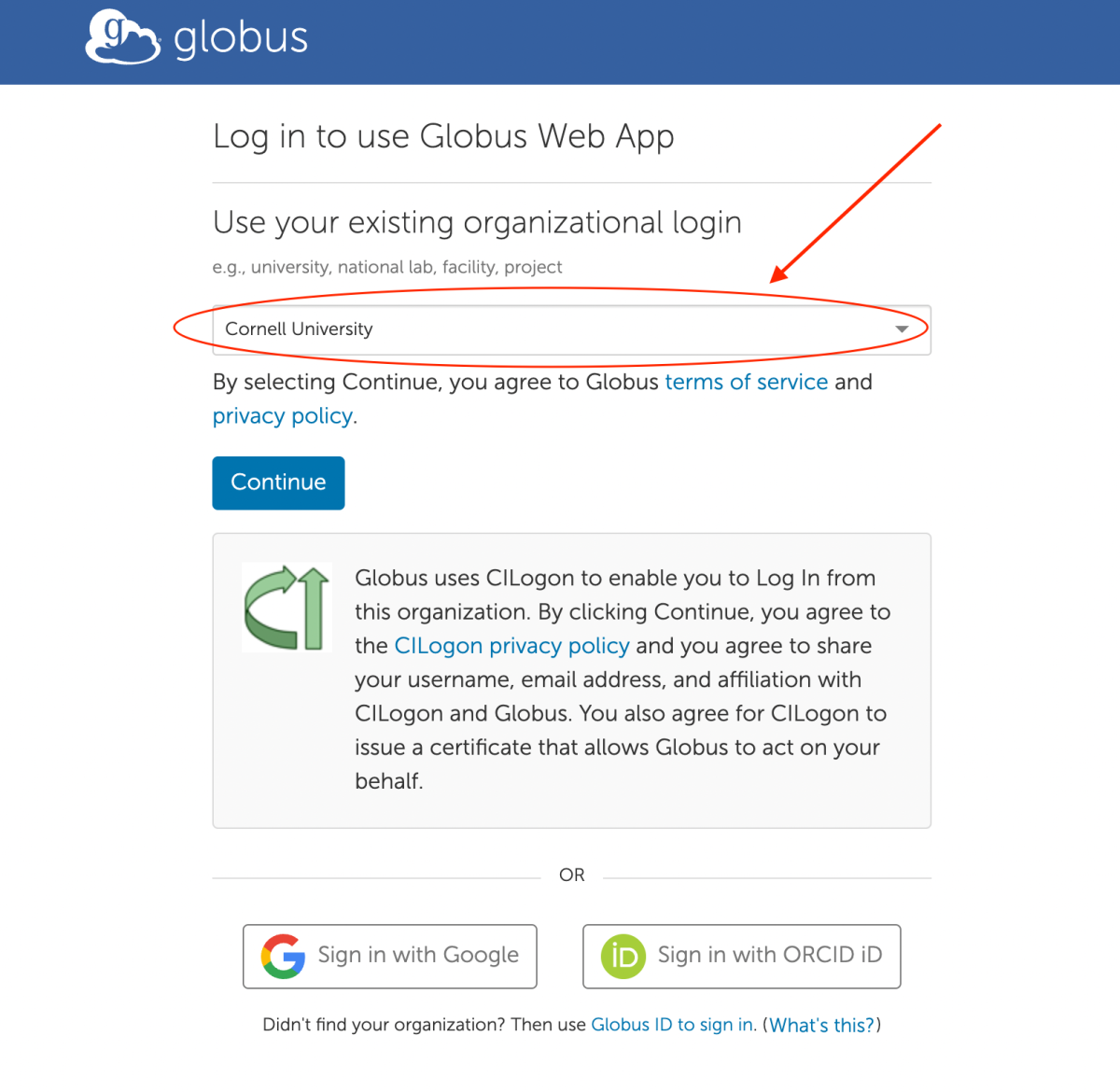
and then click on the Continue button. You will get forwarded to the CUWebLogin (Cornell users) or WCM Web Login (Weill Cornell users) page. Login using your NetID or CWID and password.
Using Globus
Globus can be accessed using the following methods:
- Globus Web GUI: click on the "Login" button on the Globus web site to start.
- Globus CLI client on your computer:
- Globus SDK for Python: for workflow automation and integration with your science gateways or third party software.
Note: The legacy ssh-based hosted CLI will be deprecated in the future. Please do not use it for new development. If you use the ssh-based CLI for current production, you will need to migrate to use new Globus CLI client or Globus SDK for Python soon.
Make Your Computer Accessible on Globus
If you want to transfer data to or from your computer, your computer needs to be a Globus endpoint:
- Globus Connect Personal: Install Globus Connect Personal to make your personal computer into a Globus endpoint.
- Globus Connect Server: If you have a multi-user Linux server, use Globus Connect Server to install a Globus endpoint accessible to all users on your server. Please read the network requirements before you start. (Basically, port 443 and ports 50000-51000 must be open to the Internet).
Globus Documentation
- Data Transfer With Globus: How it works, at a glance.
- How To Log In and Transfer Files with Globus: Sign up for a free Globus account and start transferring files, step by step.
- How To Share Data Using Globus: Specify who can access your data and what they are allowed to do with it.
CAC Archival Storage specifics
- In Globus web GUI's File Manager, select or search for the CAC Archive 2/DTN (cac#archive02) collection to access CAC archival storage.
- Each project with access to CAC Archival Storage has a shared directory (named the project) in which all project members have full read/write access.
- Users can rename and move files and directories within their project directory.